Zero-Copy CPU-GPU Pipeline Architecture for Unified Memory Systems: Design, Implementation, and Performance Analysis
Abstract
This paper presents a novel software architecture for efficient data processing pipelines between heterogeneous processors (CPU and GPU) on unified memory platforms. I introduce two complementary synchronization paradigms: event-based orchestration (V1) and persistent kernel with lock-free job queues (V2). Our approach eliminates explicit memory copies between host and device through careful exploitation of cache-coherent unified memory, atomic operations with system-wide memory ordering semantics, and a deterministic finite state machine for buffer ownership management. The architecture specifically targets the NVIDIA GB10 Grace-Blackwell platform featuring NVLink-C2C interconnect with 900 GB/s bidirectional bandwidth. I present detailed algorithmic specifications, comparative analysis of synchronization strategies, and architectural considerations for big.LITTLE ARM heterogeneous CPU configurations.
Keywords: Unified Memory, Zero-Copy, CPU-GPU Pipeline, Lock-Free Synchronization, Persistent Kernels, Heterogeneous Computing, Cache Coherence
Author: Emmanuel Forgues
1. Introduction
1.1 Motivation and Context
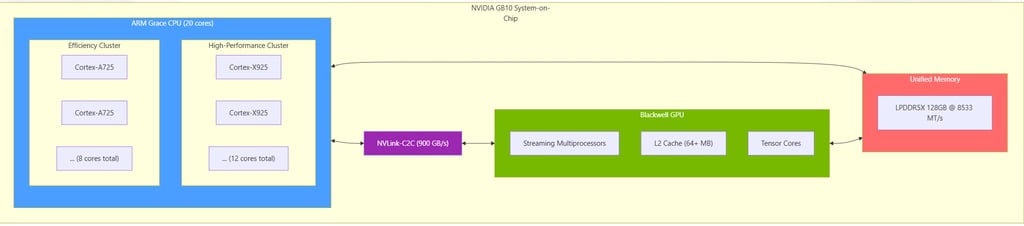
Modern heterogeneous computing systems combine general-purpose CPUs with massively parallel accelerators such as GPUs. Traditional programming models require explicit data transfers between host (CPU) and device (GPU) memory spaces, introducing significant latency and bandwidth overhead. The emergence of cache-coherent unified memory architectures, exemplified by the NVIDIA Grace-Blackwell GB10 System-on-Chip, enables a paradigm shift toward zero-copy data sharing between processors.
The GB10 platform integrates a 20-core ARM Grace CPU (heterogeneous big.LITTLE configuration) with a Blackwell GPU, connected via NVLink-C2C providing 900 GB/s bidirectional bandwidth to a shared 128GB LPDDR5X memory pool. This architectural advancement necessitates new software design patterns that fully exploit cache coherence while maintaining correct memory ordering semantics.
1.2 Problem Statement
Efficient CPU-GPU collaboration requires solving three fundamental challenges:
Ownership Management: At any instant, a shared memory region must have a clearly defined owner (CPU or GPU) to prevent data races.
Synchronization Overhead: Traditional synchronization mechanisms (CUDA events, stream synchronization) introduce microsecond-scale latencies inappropriate for fine-grained pipelines.
Cache Coherence Exploitation: Unified memory systems require explicit memory barriers to ensure visibility of writes across processor boundaries.
1.3 Contributions
This work introduces:
A five-state finite automaton for deterministic buffer ownership transitions
Two synchronization policies: host-orchestrated (EventsSync) and device-autonomous (AtomicsSync)
A persistent kernel architecture with lock-free SPMC (Single-Producer Multi-Consumer) job queue
Memory layout optimizations eliminating false sharing between metadata and payload
Algorithmic specifications for ARM big.LITTLE task scheduling
2. System Architecture Overview
2.1 Target Platform: NVIDIA GB10 Grace-Blackwell
2.2 High-Level Component Architecture
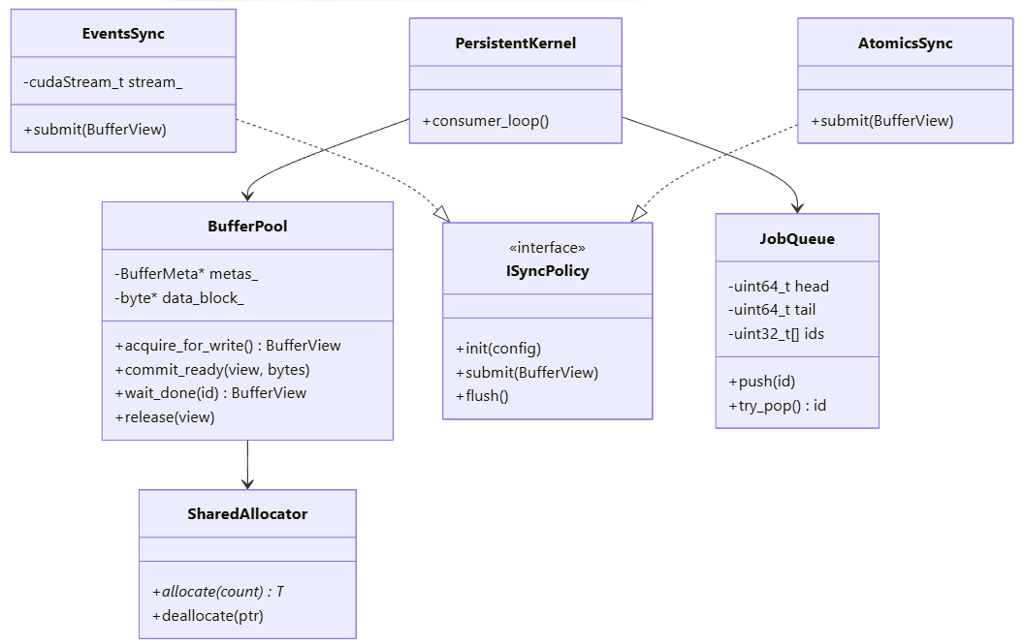
The library comprises five principal abstractions:
| Component | Responsibility |
| ------------------- | --------------------------------------------------------- |
| SharedAllocator | Unified memory allocation (cudaMallocManaged) |
| BufferPool | Pre-allocated buffer management with state tracking |
| SyncPolicy | Pluggable synchronization strategy interface |
| JobQueue | Lock-free ring buffer for persistent kernel communication |
| Pipeline | Unified API orchestrating all components |
3. Buffer Management and State Machine
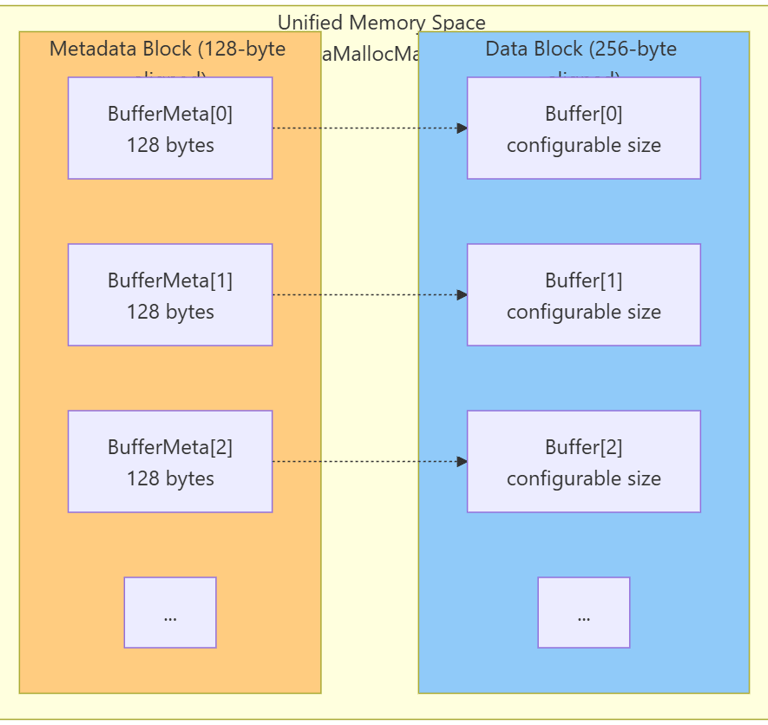
3.1 Memory Layout Design
A critical design decision separates metadata from payload to eliminate false sharing. Cache line invalidations caused by metadata updates (state transitions, sequence counters) must not affect data cachelines being read or written.
Alignment Rationale:
128-byte metadata alignment matches GPU L2 cache sector size
256-byte data alignment ensures coalesced GPU memory access
Separation guarantees that `state` and `seq_*` fields reside in distinct cachelines from payload
3.2 Buffer Metadata Structure
Each buffer carries associated metadata for synchronization:
| Field | Type | Purpose |
|-------------|-----------------|----------------------------------------------------|
| `state` | atomic<uint32_t> | Current state in the finite automaton |
| `seq_ready` | atomic<uint64_t> | Monotonic counter incremented when CPU commits |
| `seq_done` | atomic<uint64_t> | Monotonic counter incremented when GPU completes |
| `bytes_valid` | atomic<uint32_t> | Actual payload size for current job |
3.3 Five-State Finite Automaton
Buffer ownership transitions follow a deterministic finite state machine:
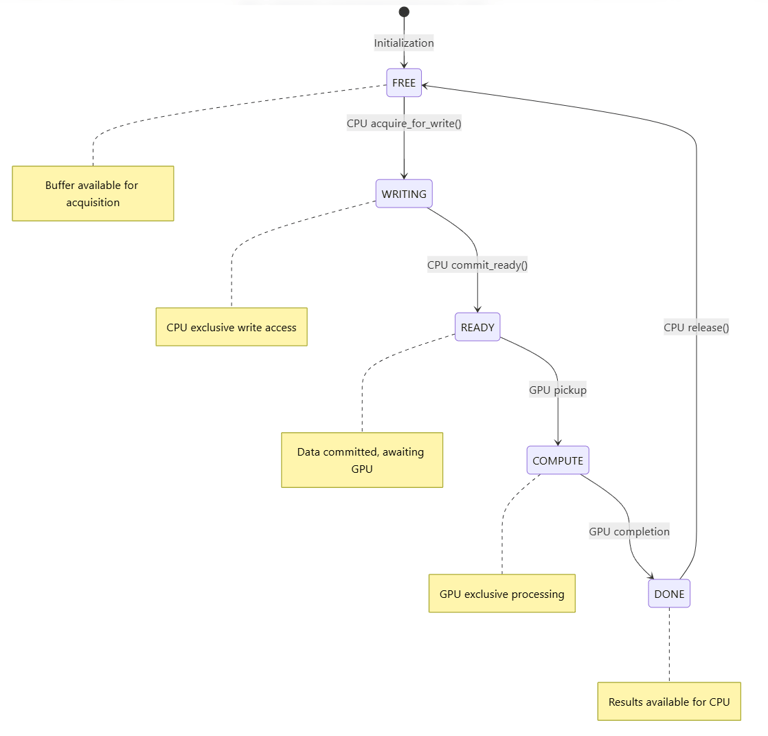
State Transition Rules:
| Transition | Actor | Precondition | Memory Ordering |
|------------------|-------|--------------------------------|-----------------|
| FREE -> WRITING | CPU | CAS(state, FREE\|DONE, WRITING) | acquire-release |
| WRITING -> READY | CPU | After data write completion | release |
| READY -> COMPUTE | GPU | seq_ready observed | acquire |
| COMPUTE -> DONE | GPU | After kernel completion | release |
| DONE -> FREE | CPU | After result consumption | release |
---
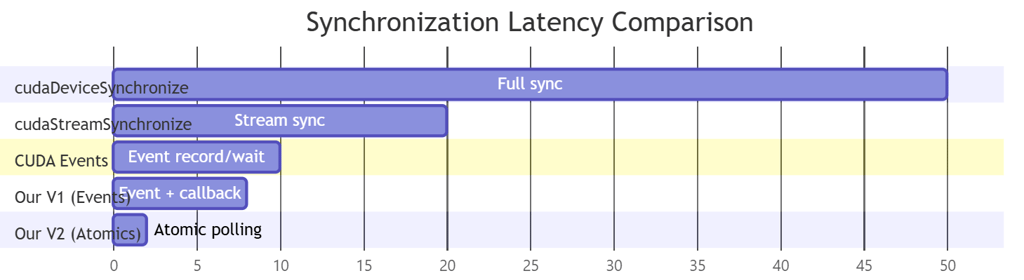
4. Synchronization Strategies
4.1 Strategy Comparison
We implement two distinct synchronization paradigms with complementary characteristics:
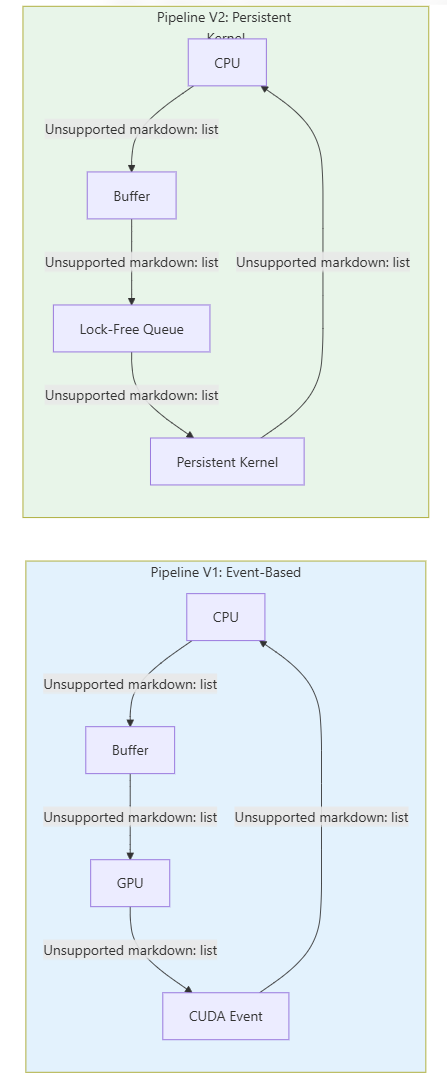

| Characteristic | EventsSync (V1) | AtomicsSync/Persistent (V2) |
|-----------------------------|---------------------------|------------------------------|
| Kernel launch overhead | Per-job (3-10 us) | Once at startup |
| Synchronization mechanism | CUDA Events + Host callbacks | Atomic flags + polling |
| CPU blocking | Yes (event wait) | Optional (polling) |
| Minimum latency | ~5-10 microseconds | ~0.5-2 microseconds |
| Implementation complexity | Low | High |
| Debugging difficulty | Low | High |
| Resource utilization | Variable SM occupancy | Dedicated SM reservation |
4.2 Event-Based Synchronization (V1)
The event-based strategy uses CUDA's native synchronization primitives:
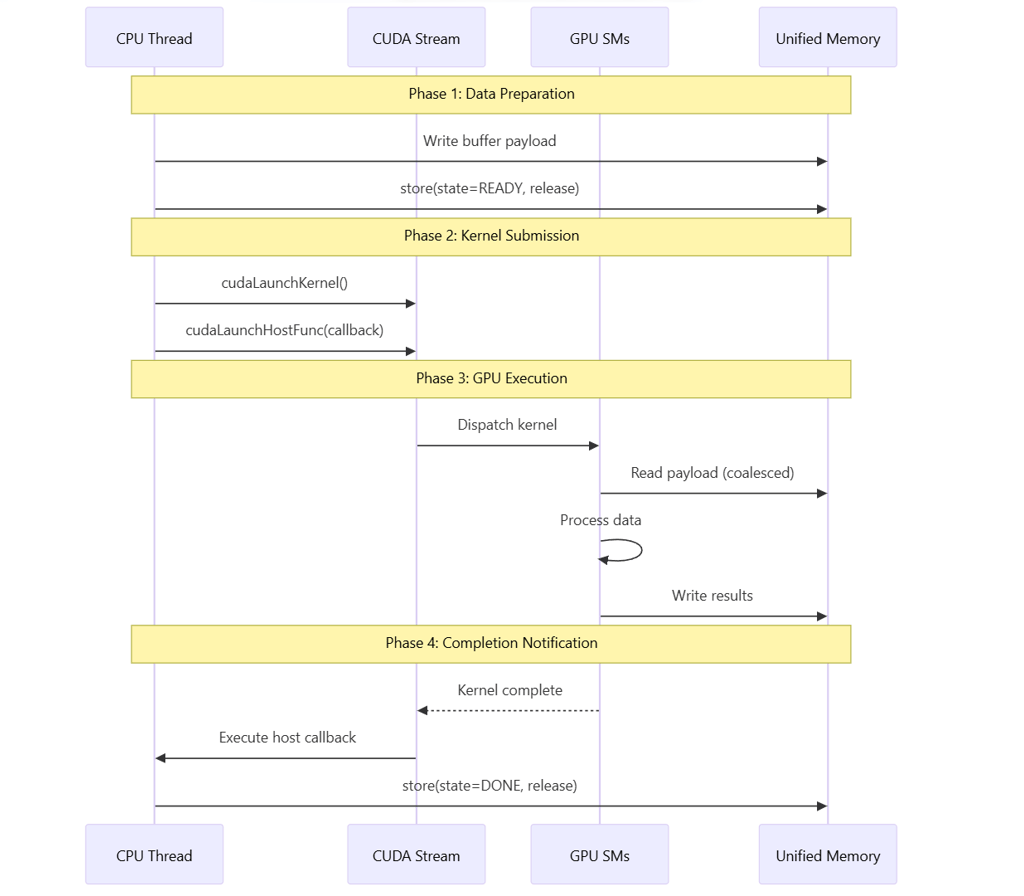



4.3 Atomic-Based Synchronization with Persistent Kernel (V2)
The persistent kernel strategy eliminates per-job launch overhead:








5. Memory Ordering and Coherence Protocol
5.1 Memory Barrier Requirements
Cache-coherent unified memory does not eliminate the need for explicit memory ordering. The following barriers ensure correct visibility:
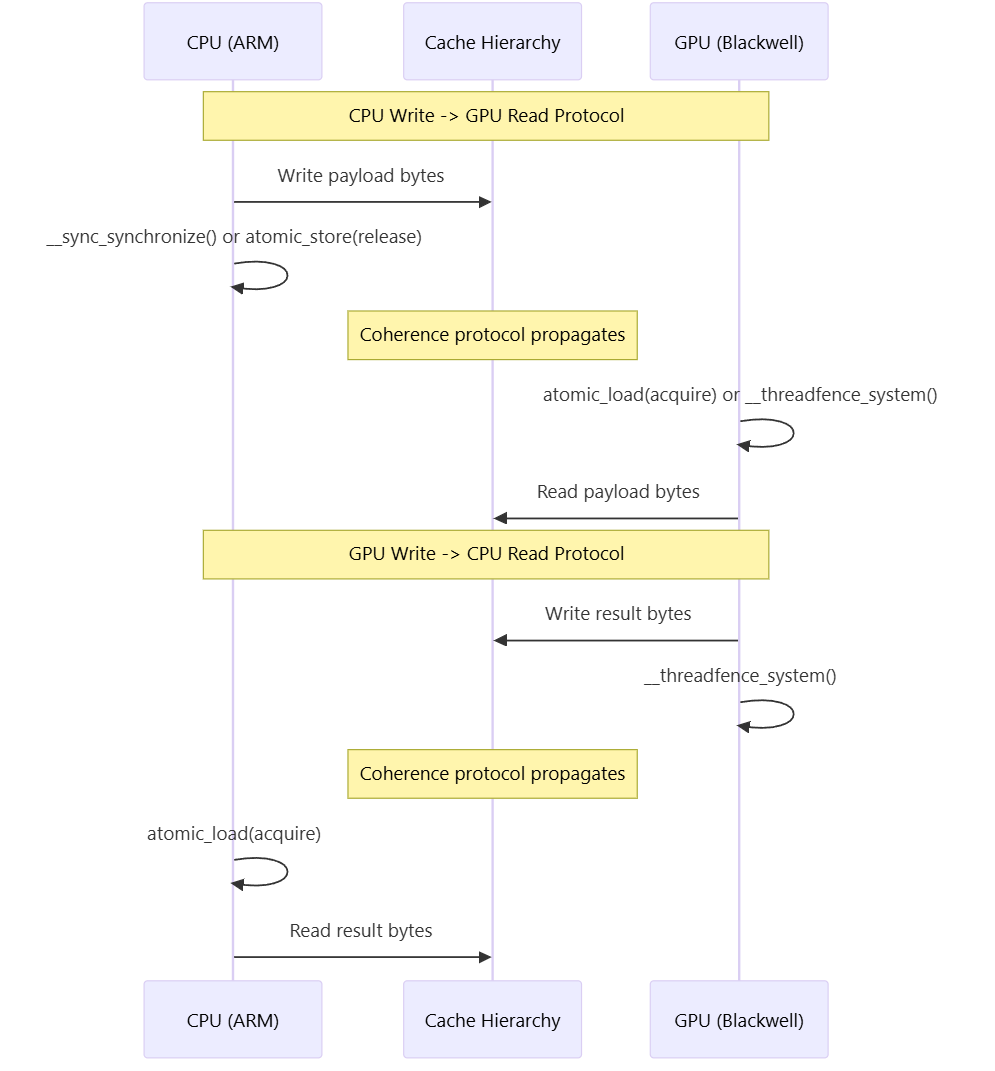
5.2 Memory Ordering Semantics


5.3 Adaptive Backoff Strategy
Polling-based synchronization requires careful backoff to balance latency against power consumption:
Algorithm: Adaptive Backoff (GPU)


6. ARM big.LITTLE Task Scheduling
6.1 Heterogeneous Core Utilization
The GB10's ARM Grace CPU employs a big.LITTLE architecture requiring workload-aware scheduling:
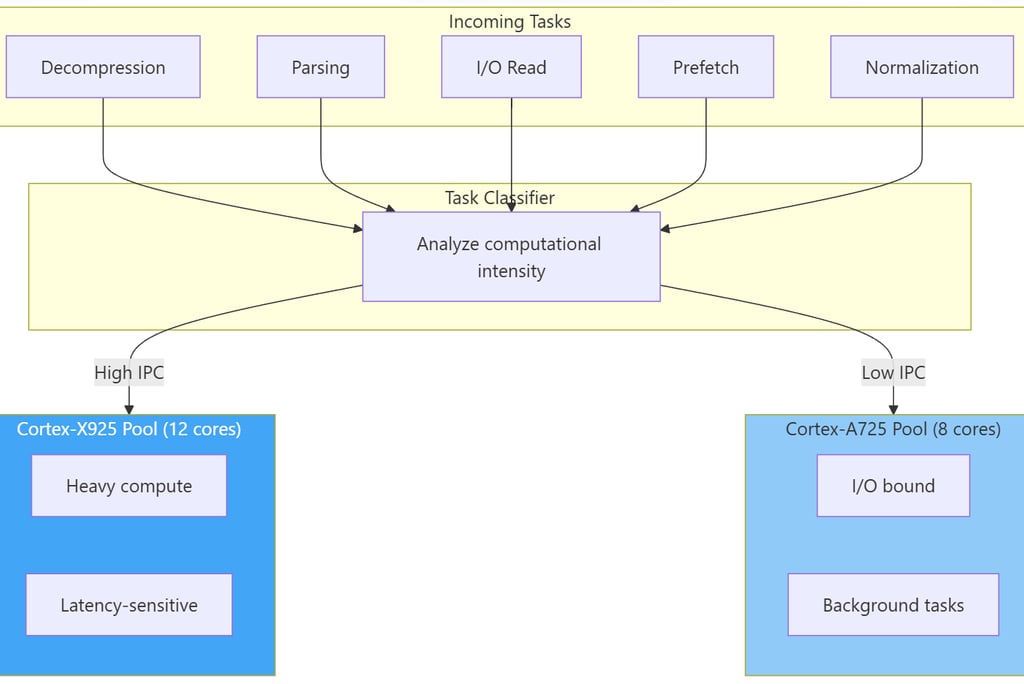

6.2 Task Classification Criteria


7. Performance Model and Analysis
7.1 Latency Components
The end-to-end latency for processing a single buffer comprises:


7.2 Throughput Model
For a pipeline with N buffers processing jobs of size S bytes:
Maximum Throughput (Event-Based V1):


8. Comparative Analysis with Traditional Approaches
8.1 Memory Transfer Comparison