Lib UnifiedFlow
Lib UnifiedFlow is a C++/CUDA library optimized to leverage the unified CPU-GPU architecture of the NVIDIA GB10 (Grace-Blackwell). It enables high-performance data processing pipelines with zero-copy between the ARM CPU and Blackwell GPU.
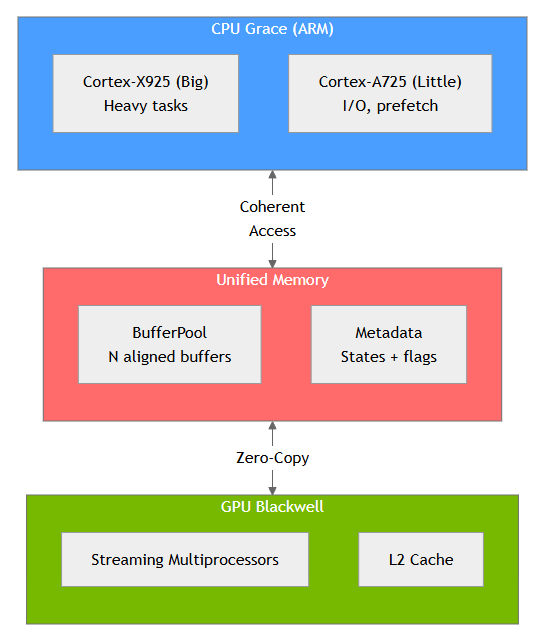
Unified Memory
Leverages Grace-Blackwell coherent memory without explicit copies
Zero-Copy Pipeline
Buffers are simultaneously accessible by CPU and GPU
Big.LITTLE Aware
Smart task distribution between Cortex-X925 and A725 cores
Lock-Free
Atomic synchronization without mutexes to minimize latency
Global Architecture
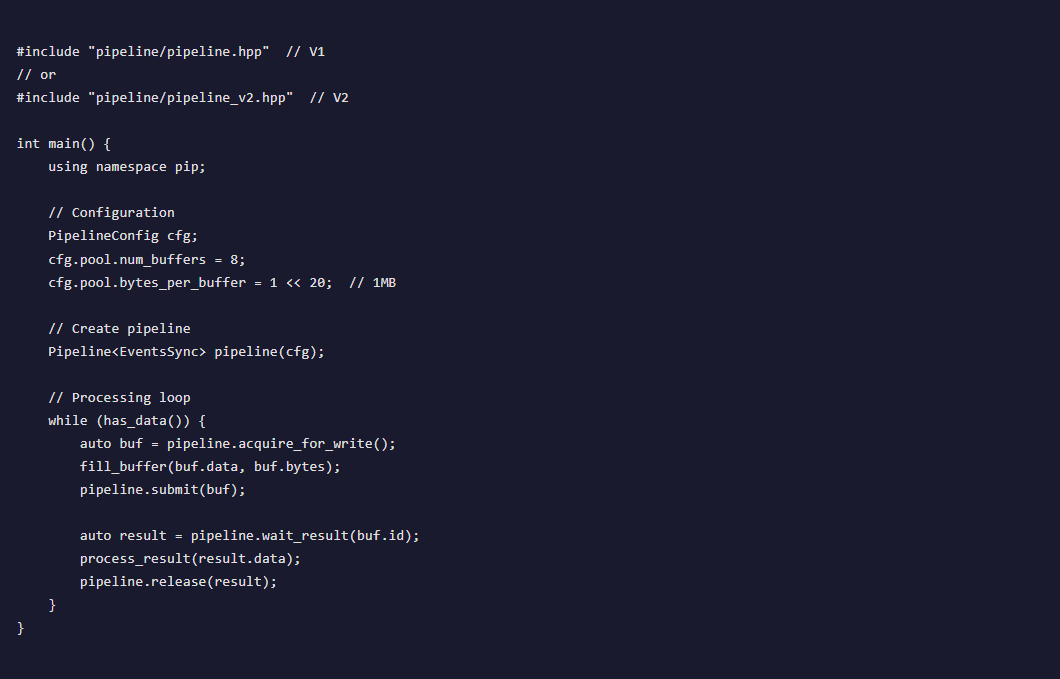
Quick Start
Two Versions
V1 - Event/Atomics Sync
Classic pipeline with CUDA events or atomic polling synchronization.
One kernel per job
Low latency
Simple to use
V2 -Persistent Kernel
Persistent GPU kernel with lock-free job queue.
Always-on kernel
Maximum throughput
SPMC ring buffer
V1 vs V2 Comparison


V3.0.1 Pro (NEW)
Sweet spot valide: 4.7-5.2x pour buffers < 512KB
Peak: 5.16x a 128KB (378 MB/s)
Max throughput: 15.9 GB/s a 32MB (fire-and-forget)
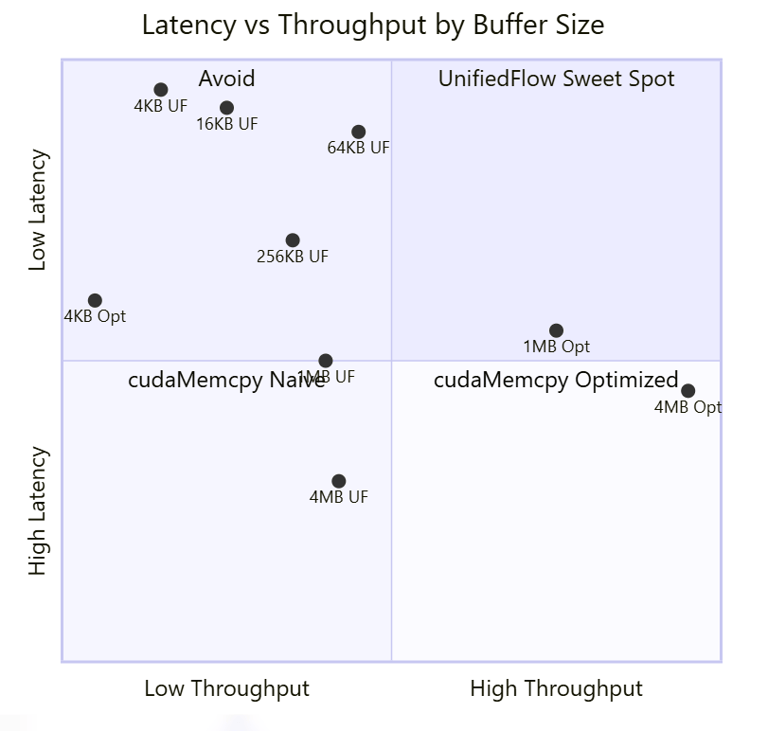
Latency vs Throughput Trade-off
Latency vs Throughput Trade-off
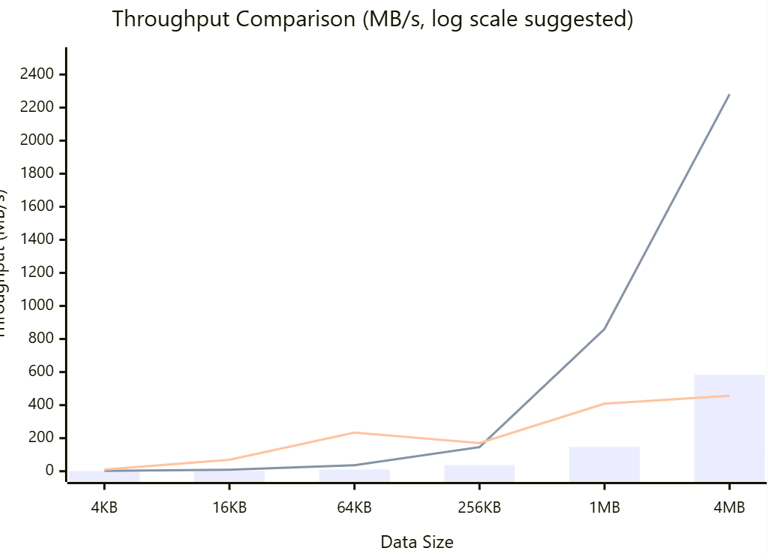
Legend
Bar (grey): Baseline Naive (sync per job)
Line 1 (blue): Baseline Optimized (4-buffer pipelining)
Line 2 (green): UnifiedFlow v2.3
Zero-Copy CPU-GPU Pipeline Architecture for Unified Memory Systems: Design, Implementation, and Performance Analysis
Abstract
This paper presents a novel software architecture for efficient data processing pipelines between heterogeneous processors (CPU and GPU) on unified memory platforms. We introduce two complementary synchronization paradigms: event-based orchestration (V1) and persistent kernel with lock-free job queues (V2). Our approach eliminates explicit memory copies between host and device through careful exploitation of cache-coherent unified memory, atomic operations with system-wide memory ordering semantics, and a deterministic finite state machine for buffer ownership management. The architecture specifically targets the NVIDIA GB10 Grace-Blackwell platform featuring NVLink-C2C interconnect with 900 GB/s bidirectional bandwidth. We present detailed algorithmic specifications, comparative analysis of synchronization strategies, and architectural considerations for big.LITTLE ARM heterogeneous CPU configurations.
Keywords: Unified Memory, Zero-Copy, CPU-GPU Pipeline, Lock-Free Synchronization, Persistent Kernels, Heterogeneous Computing, Cache Coherence
Author : Emmanuel Forgues
UnifiedFlow v3.0.1 Pro: High-Performance CPU-GPU Data Pipeline
Abstract
UnifiedFlow v3.0.1 Pro is a production-ready library designed for high-throughput, low-latency CPU-GPU data transfers on NVIDIA Grace-Blackwell (GB10) architecture. By leveraging CUDA Unified Memory with persistent GPU kernels, UnifiedFlow achieves 4.7-5.2x speedup over optimized cudaMemcpy for buffer sizes under 512KB, while automatically routing larger transfers to DMA engines for optimal throughput.
Keywords: Unified Memory, Zero-Copy, CPU-GPU Pipeline, Lock-Free Synchronization, Persistent Kernels, Heterogeneous Computing, Cache Coherence
Author : Emmanuel Forgues



